
Please note that while we offer a full refund, a small 5% processing fee is applied to cover non-refundable transaction fees initially absorbed by us to facilitate your purchase.

Thank you for purchasing one of our courses on Udemy! Now that you have experienced the PrepNuggets way of learning, are you ready to take your exam prep to the next level with us?
We have an irresistible offer for you to upgrade to our Level I Premium Membership, where you will gain full access to ALL 10 topical courses under the CFA Level I curriculum.
Simply log in to any of our courses on Udemy, and head to the last lecture titled ‘BONUS: Continue Your Exam Prep With Us!‘. You will find the exclusive link to sign up for this offer!


Have you ever gotten stuck in your study because you can’t remember a formula, or what a specific term means? Now, say goodbye to scanning through all the videos and ploughing through pages and pages just to find what you are looking for. All the important formulas, definitions and diagrams you need for the exam are now at your fingertips at prepnuggets.com/glossary.
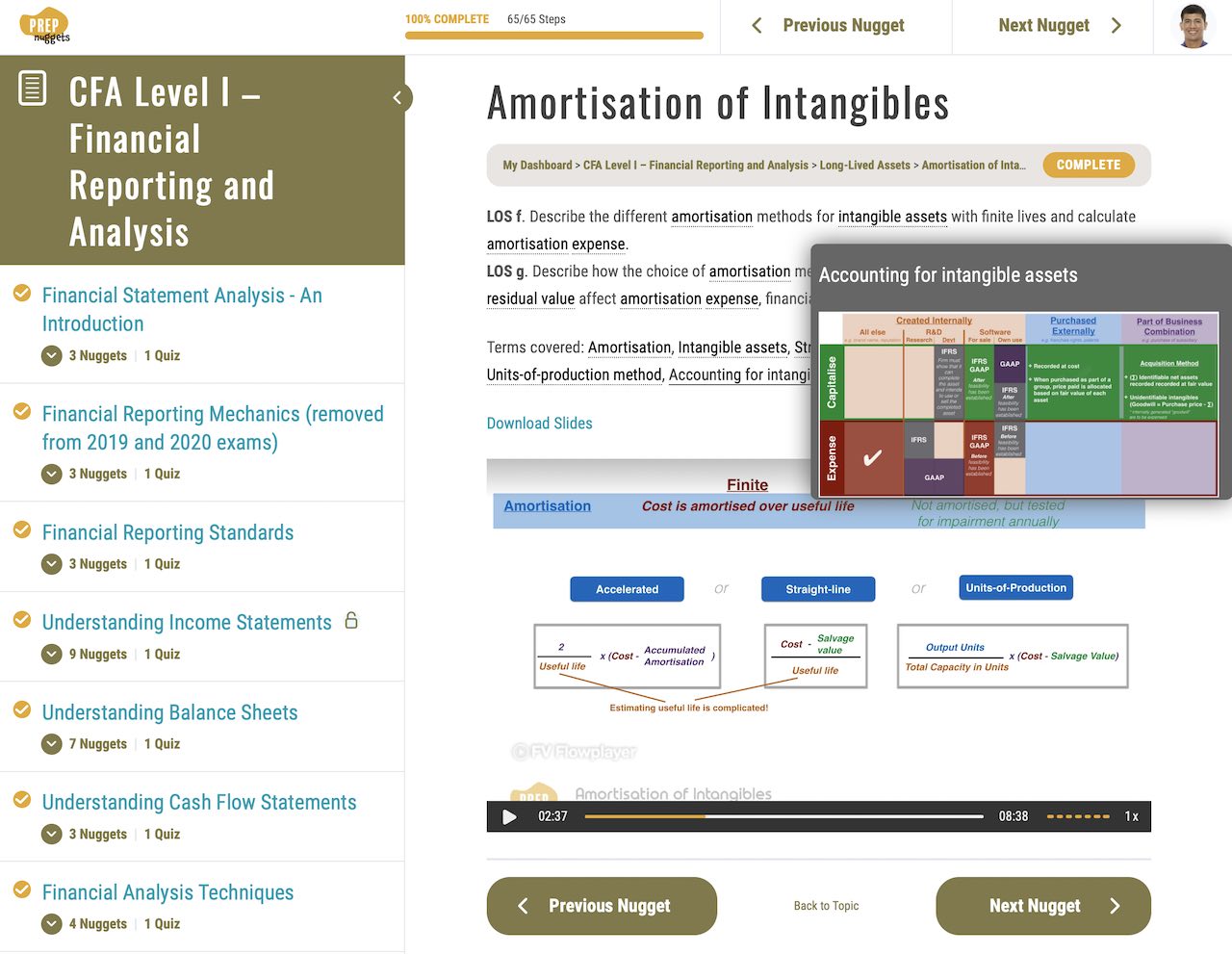
What’s more, these quick references are deeply integrated in our lessons, so you get a good idea of what the lesson covers even before watching the video. The references also point you to specific video lessons where it is covered, so you can quickly access the corresponding video to learn more about the term.
Available now for all Level I topics, this service is exclusive for our Premium and Pro members only. We will progressively add the rest of the topic areas over the next few months.
We think this is a game-changer for your CFA success!

On the 1st of March 2018, we took a bold step of faith to put our Financial Reporting and Analysis (FRA) course on Udemy.
For those of you who are new to Udemy, it is the world’s largest marketplace for online courses. Think of it like the EBay of online courses.
So imagine our trepidation in pitting our course in this highly competitive platform, against the many CFA prep providers already entrenched on the platform.
Overwhelming.
Yes, that’s the word that aptly describes the response to our course from the Udemy community.

The “Best Seller” tag from Udemy is attached to only one best selling course in its category. In just 1 month, our FRA course became the best selling CFA course on the platform. If you do a search for ‘CFA Level 1’, our course comes out on top in the search rankings.

Since the launch on 1 March, we have had more than 250 paid enrolments. While we are heartened by this figure, nothing beats knowing that our course has reached 50 countries around the world! It was simply heartwarming to receive messages from students from countries we barely know about, telling us how much they love the course and their wish that we would produce more of such courses. This certainly spurs us on to produce more materials to ease the burden of CFA candidates worldwide.

As of today, our course has a high average rating of 4.8 out of 5.0. 74% of the reviewers gave us 5 stars! We take this as endorsement that we are doing things right, and will continue in using the Pareto principle approach for our course materials. There are, of course, constructive feedback as well, and we aim to incorporate some of the feedback in producing the upcoming courses.
We are working hard to bring more of our courses to Udemy! We realise some candidates prefer to purchase courses as they need individually, so we endeavour to give more options to our potential students. Check out our Udemy Courses Page to find out which of our courses are available on Udemy for your purchase.
If you have purchased our course on Udemy and would like to continue with the PrepNuggets study approach for other topics, we have an awesome upgrade offer to Premium membership for you!
Many years ago, I was exactly where you are today—a CFA Level I candidate juggling a demanding full-time career with the daunting CFA curriculum. Coming from a Computer Engineering background, finance was entirely new territory for me. And yes, it was tough!
I struggled with dense textbooks, late-night cramming, and the frustration of concepts that seemed impossible after a long workday. But after passing Level I (barely), I realized something had to change.
Using the Pareto Principle (80/20 rule), I distilled the vast CFA syllabus into essential, easy-to-understand nuggets. I leaned into visual summaries and bite-sized learning sessions that worked around my busy schedule. This smarter approach helped me clear Levels II and III on my first attempts with significantly less stress.
I founded PrepNuggets to share the streamlined strategies and innovative learning methods that transformed my CFA journey. Our mission is simple: leverage technology to make CFA prep more effective, accessible, and enjoyable.
Join the PrepNuggets community today—sign up for your free account, and let our thoughtfully crafted materials propel you toward CFA success without unnecessary overwhelm.
Here’s to your CFA journey!
Keith Tan, CFA
Founder & Chief Instructor, PrepNuggets
[theme-my-login show_reg_link=”0″]
[theme-my-login default_action=”register” show_title=”false”]