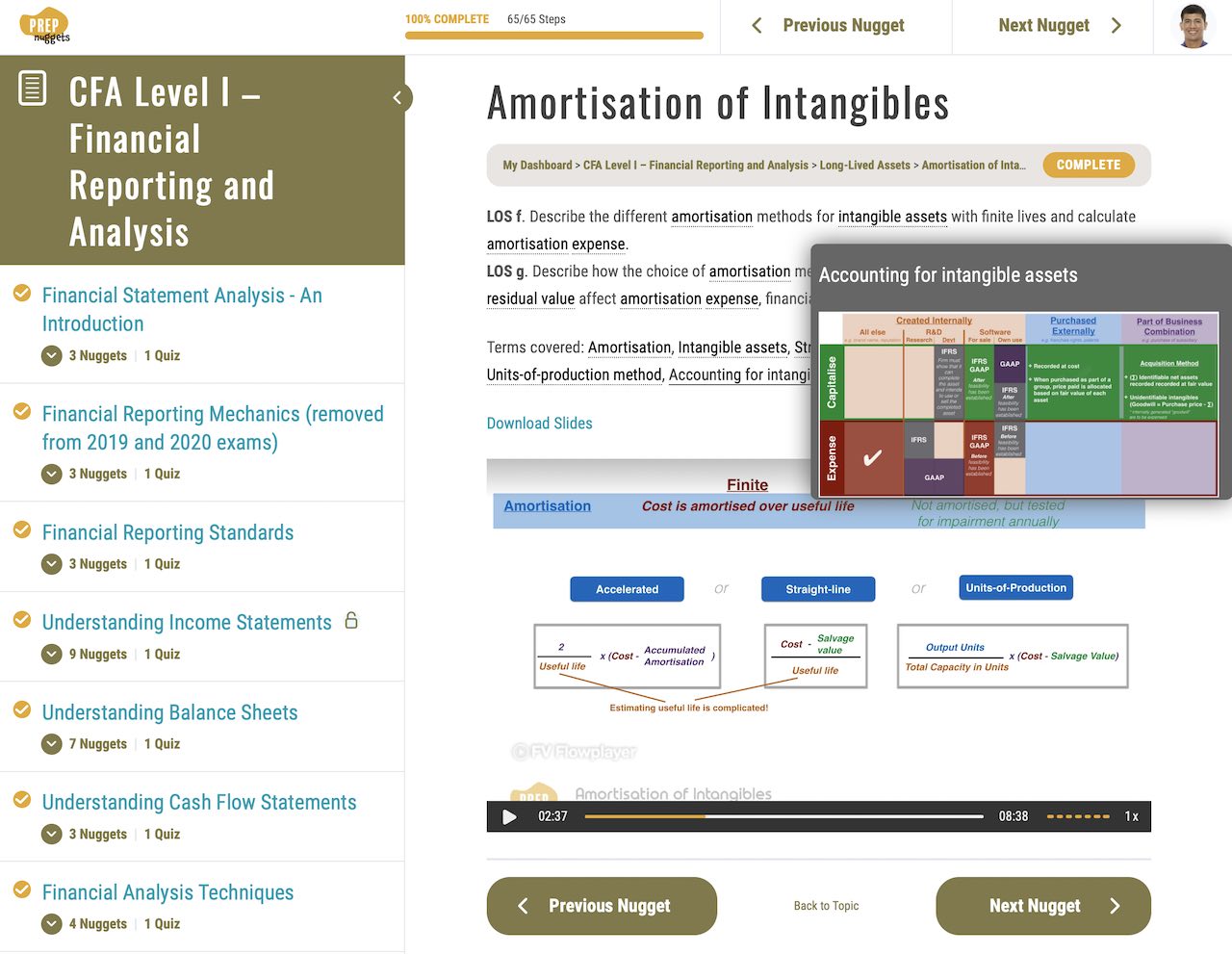
Understanding Hypothesis Testing for Linear Regression | CFA Level I Quantitative Methods
In our last lesson, we ended off by learning how to calculate the confidence interval of a forecast made by our linear regression model. Besides the uncertainty of the forecast, there are other uncertainties of the estimates that are of interest, like the intercept and slope coefficient. In this lesson, we apply the statistical tools on the slope coefficient, but the same tools can be applied on the intercept as well.
Setting up Hypothesis Testing for Slope Coefficient
Let’s say you believe that there is a relationship between the company profit and the bonus payouts. Your alternate hypothesis (Ha) should be that the slope coefficient b1 ≠0. This is because if there is a relationship, the slope coefficient should be significantly different from zero. Your null hypothesis (H0) should therefore be b1=0, which implies there is no relationship between the company profits and bonus.
Using Confidence Interval for Hypothesis Testing
EXAMPLE
Calculating the 95% Confidence Interval for the Slope Coefficient Estimate:

Step 1: Point Estimate
The point estimate is simply the slope coefficient, which we estimate as 0.3.
Step 2: Critical Value
We use the t-statistic here, with a degree of freedom of n-2 as there are two estimated parameters in a simple linear regression. With 2 degrees of freedom and a two-tailed significance level of 5%, we get a critical value of 4.303.
Step 3: Standard Error
Let’s say we are told that the standard error for the coefficient is 0.18.
Step 4: Calculating the 95% Confidence Interval
Plugging in all the figures into the confidence interval formula, we get an interval of between -0.47 and 1.07.
Lower Bound: 0.3 – (4.303 × 0.18) = -0.47
Upper Bound: 0.3 + (4.303 × 0.18) = 1.07
Since zero falls within the confidence interval, we are unable to reject the null hypothesis. This means that at the 95% confidence level, there is insufficient evidence to support your hypothesis that there is a linear relationship between company profit and bonus payouts.
Using t-test for Hypothesis Testing
Another approach is to simply use a t-test, whereby we calculate the t-statistic, which is to measure how many standard deviations our estimate is away from the hypothesized value. In our example, we get a t-statistic = (0.3 / 0.18) = 1.667.

Since our t-statistic (1.667) is not within the rejection region (critical value of 4.303), we fail to reject the null hypothesis. We cannot conclude that there is a positive relationship between company profits and the number of months bonus at the 5% significance level.
Hypothesis Testing with TinyPower Example
EXAMPLE

p-value and Hypothesis Testing
In hypothesis testing, the choice of significance level is always a matter of judgment. If we use a higher significance level, we may be able to reject the null hypothesis. However, that also increases the probability of a Type 1 error, which is the probability of rejecting the null hypothesis when it is actually true. On the flip side, if we use a significance that is too low, the probability of a Type 2 error increases, that is failing to reject the null hypothesis when it is actually false.
So rather than reporting whether a particular hypothesis is rejected or not, some analysts prefer to report the p-value or probability value for the reader to interpret the results. The p-value is the smallest level of significance at which the null hypothesis can be rejected. In our example, the t-statistic 1.667 we calculated earlier falls somewhere between probabilities of 0.2 and 0.3 on the t-table, so the p-value is around 0.24. This means that we can reject the null hypothesis at around the 24% significance level. This figure allows the reader to form his own opinion with regards to the hypothesis. As in this case, the reader may find that the p-value is too high, so he may disregard the findings of the hypothesis.

Understanding the F-Test in Linear Regression
In this lesson, we will explore the F-test in linear regression analysis and discuss some limitations of regression analysis. The F-test is used to determine if there is a significant relationship between the independent and dependent variables in a linear regression model.
F-Test and the ANOVA Table
First, let’s recap the ANOVA table from our previous lesson. The table consists of explained and unexplained variation:
- Explained variation (Regression Sum of Squares – RSS): The portion of the total variation that is explained by the regression model.
- Unexplained variation (Sum of Squared Errors – SSE): The portion of the total variation that remains unexplained by the regression model.
The F-statistic is calculated as follows:
F-statistic = Mean Square Regression (MSR) / Mean Square Error (MSE)
A high F-statistic indicates that the linear regression is a good fit, suggesting a significant relationship between the independent and dependent variables.
EXAMPLE
Given an ANOVA table with the following values: n = 4, SSE = 0.86, RSS = 6.9. Calculate the F-statistic and determine if there is a significant relationship between the dependent and independent variables at a 5% level of significance.

Calculate the degrees of freedom (DF) for explained and unexplained variation:
DF1 (explained) = 1, DF2 (unexplained) = N – 2 = 4 – 2 = 2
Calculate the MSR and MSE:
MSR = RSS / DF1 = 6.9 / 1 = 6.9
MSE = SSE / DF2 = 0.86 / 2 = 0.43
Calculate the F-statistic:
F-statistic = MSR / MSE = 6.9 / 0.43 = 16.05
To determine if the F-statistic is significant, we compare it to the critical value from the F-table:
Find the critical value for a 5% level of significance with DF1 = 1 and DF2 = 2. The critical value is 18.5. Since 16.05 < 18.5, we cannot reject the null hypothesis. There is no significant relationship between the dependent and independent variables at the 5% level of significance.
✨ Visual Learning Unleashed! ✨ [Premium]
Elevate your learning with our captivating animation video—exclusive to Premium members! Watch this lesson in much more detail with vivid visuals that enhance understanding and make lessons truly come alive. 🎬
Unlock the power of visual learning—upgrade to Premium and click the link NOW! 🌟