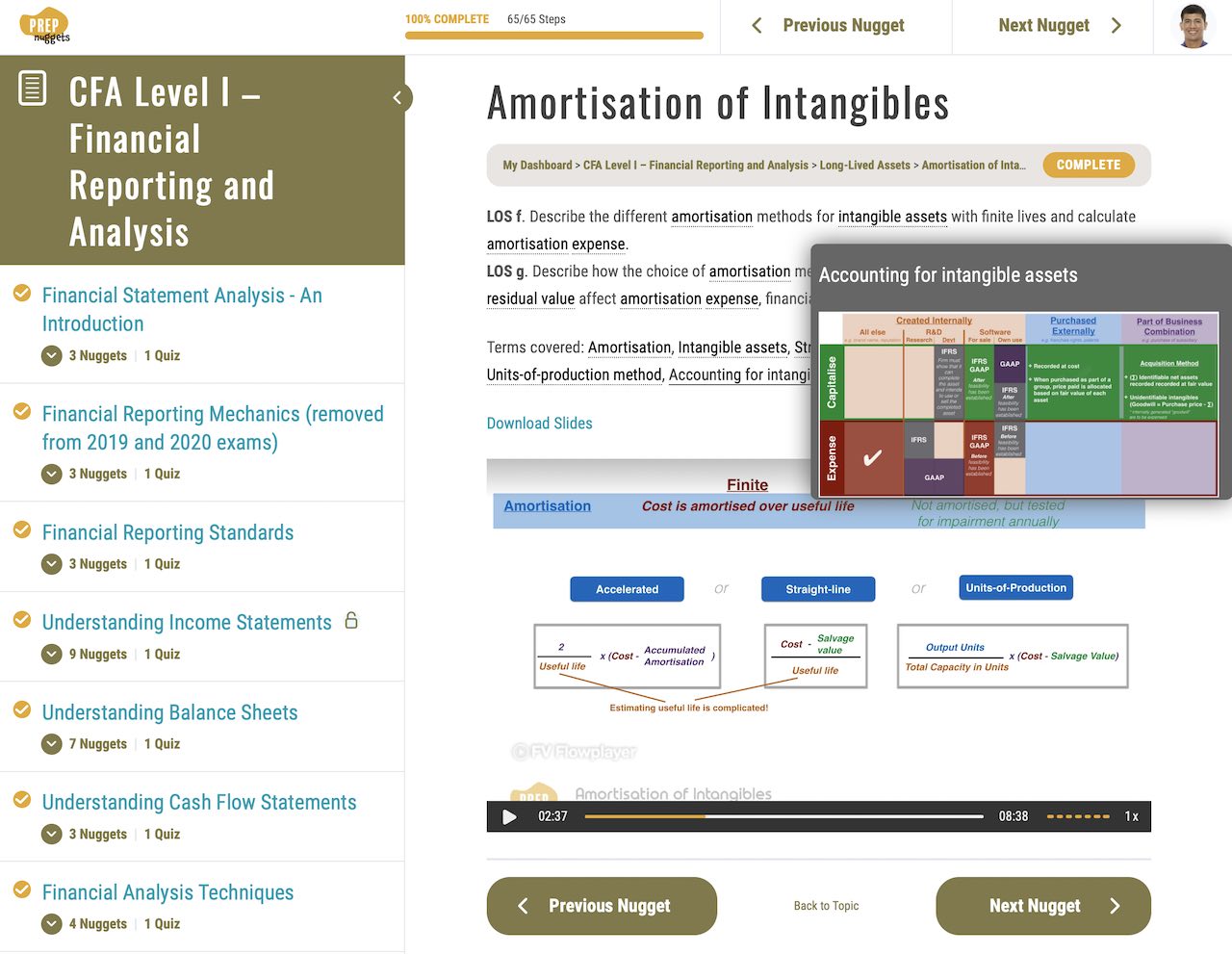
Confidence in Simple Linear Regression | CFA Level I Quantitative Methods
Analysis of Variance (ANOVA)
ANOVA is a statistical procedure for analyzing the total variability of the dependent variable. To understand it better, let’s break down the components of our regression model:
- Total Sum of Squares (SST): The sum of the squared differences between the actual values and the mean of the dependent variable.
- Regression Sum of Squares (RSS): The portion of the total variation that is explained by the regression model, calculated as the sum of the squared distances between the values from the model and the mean.
- Sum of Squared Errors (SSE): The sum of the squared differences between the actual data points and the estimates from the model. The least squares method of regression allows us to find the straight line that minimizes the SSE.

The relationship between these components is as follows:SST = RSS + SSE
The total variation is the sum of the explained variation and the unexplained variation.
ANOVA Table
The ANOVA table allows us to determine how fitting the regression model is to the observed data, which is a factor in how confident we are of the estimations given by the model. In statistics, there is the concept of degrees of freedom:
- Total degrees of freedom: n – 1, where n is the number of observations.
- Degrees of freedom for the regression: k, which is the number of parameters (in this case, 1 for simple linear regression).
- Degrees of freedom for the error: n – k – 1 (for a simple linear regression, n – 2).

To calculate the mean of the sum of squares, we divide the sum of squares by the degrees of freedom:
- Mean of the Regression Sum of Squares (MSR): MSR = RSS / k. For a simple linear regression, the MSR is simply equal to the RSS.
- Mean of the Sum of Squared Errors (MSE): MSE = SSE / (n – 2).
And that’s the ANOVA table! It helps us evaluate the goodness of fit of our regression model and, ultimately, the confidence we can have in our estimations.
With this foundation, we’re ready to explore SEE and R-squared.
Measuring Model Fit: SEE and R-squared
There are two approaches to determine the fit of our model:
1. Standard Error of Estimate (SEE)
The first approach is to measure the standard deviation of the error term, which is equal to the square root of the Mean Squared Error (MSE). This is called the Standard Error of Estimate (SEE). Be mindful of the distinction between SEE and SSE (Sum of Squared Errors).
2. Coefficient of Determination (R-squared)
The second approach is to measure how well the model explains the variations. We do this by computing the coefficient of determination (R-squared), which is simply the proportion of total variation that can be explained by the regression variation from the mean.
Interpreting SEE and R-squared:
- Low SEE and high R-squared indicate a good fit, meaning we should have a higher confidence in the estimates.
- High SEE and low R-squared indicate a poor fit, and our confidence in the estimates should be low.
EXAMPLE

Constructing Confidence Intervals for Forecasts
Calculating the confidence interval of a particular prediction given by the model can provide an even more precise measure. The confidence interval consists of a point estimate, +/- critical value for a particular significance level multiplied by the standard error.

Important notes:
- Use the t-statistic with a degree of freedom of n-2.
- Standard error of the forecast ≠ SEE. The standard error of the forecast includes errors in the estimation of the intercept and the slope coefficient.
EXAMPLE

✨ Visual Learning Unleashed! ✨ [Premium]
Elevate your learning with our captivating animation video—exclusive to Premium members! Watch this lesson in much more detail with vivid visuals that enhance understanding and make lessons truly come alive. 🎬
Unlock the power of visual learning—upgrade to Premium and click the link NOW! 🌟